
Open Compass
PSC Compass Program
Accelerating Discovery with Emerging AI Technologies
PSC’s Compass Program focuses on the application of AI technologies to address open challenges in research. It consists of four main components: the Compass Center, Compass Lab, Compass Consortium, and Open Compass.
Compass Center
The Compass Center brings together faculty, staff, and members from industry, government, academic and nonprofit organizations to advance AI research and development and accelerate the adoption of AI across various fields, industries, and sectors of society.
Compass Lab
The Compass Lab provides unique access through PSC to new hardware and software technologies for AI, backed by human expertise and partnering with faculty thought leaders to develop solutions.
Compass Consortium
The Compass Consortium provides, depending on the level of membership, access to seminars, meetings, presentations, publications, reports, case studies, technical briefings, and benchmark results; access to consortium projects; member-directed projects emphasizing the application of new AI technologies to derive value from data; networking with faculty, students, vendors, and other members; connections to domain experts; training; input through an advisory board to define consortium projects; and other benefits.
Open Compass
Open Compass is an exploratory research project to conduct academic pilot studies on an advanced engineering testbed for artificial intelligence, the Compass Lab, culminating in the development and publication of best practices for the benefit of the broad scientific community. It also provides expert assistance in applying Compass Lab resources and collaborative development of algorithms, models, and software; develops and disseminates best practices; and provides training tailored to the open research community.
Open Compass includes the development of an ontology (see Figure 1) to describe the complex range of existing and emerging AI hardware technologies and the identification of benchmark problems that represent different challenges in training deep learning models. These benchmarks are then used to execute experiments in alternative advanced hardware solution architectures.
Below we present the methodology of Open Compass and some preliminary results on analyzing the effects of different GPU types, memory, and topologies for popular deep learning models applicable to image processing.
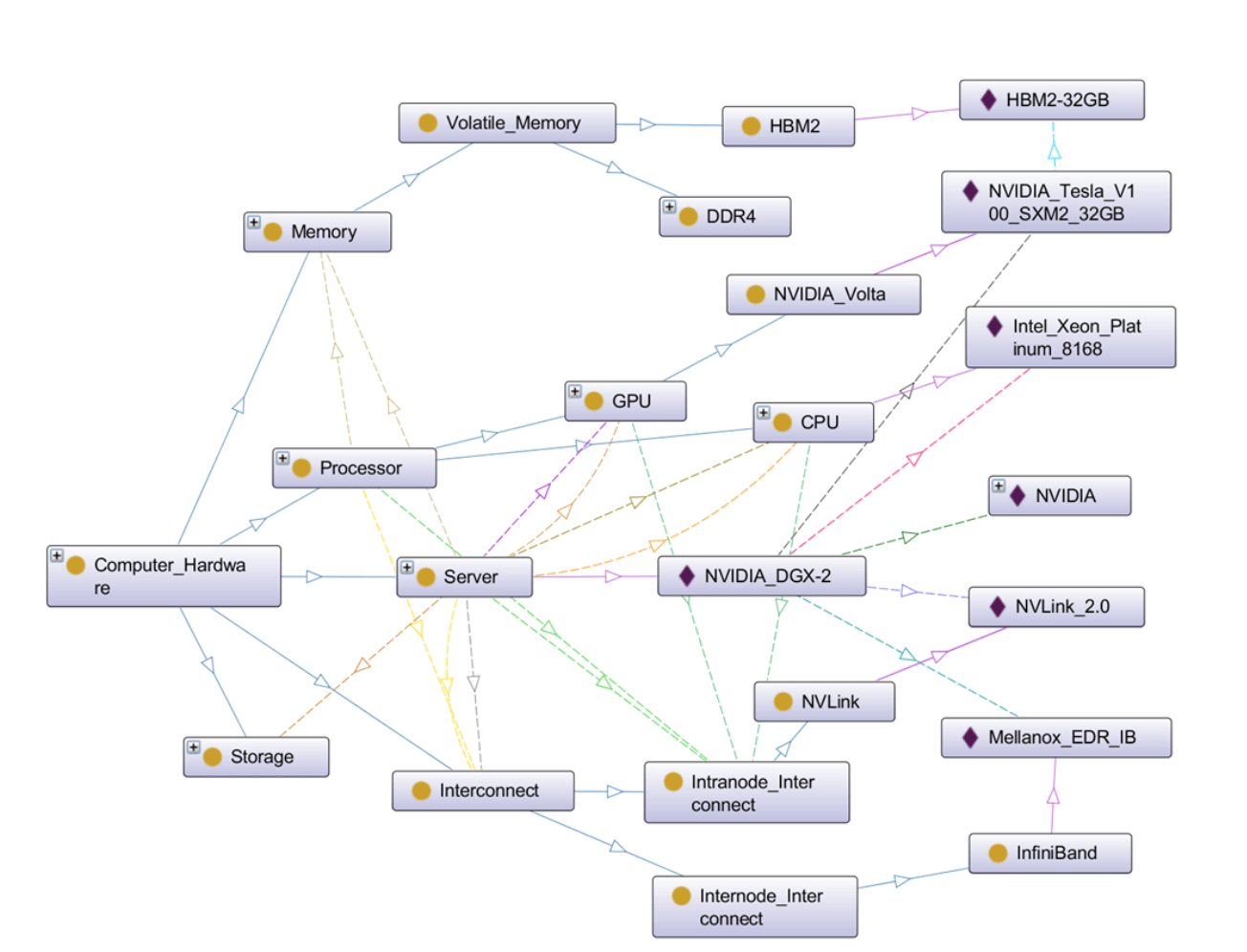
Figure 1. Example visualization of the Compass ontology, focused on an individual NVIDIA DGX-2 class server. Solid arcs indicate subclass relationships, and dashed arcs indicate object properties such as GPU type and internal interconnect type.
Performance Experiments
Open Compass addresses both training and inferencing, initially focusing on training neural networks for image processing for its familiarity to the community and to document our methodology. Performance results for training five neural networks have been reported, InceptionV3, ResNet-50, ResNet-152, and VGG16, and AlexNet, all using synthetic data. These networks differ significantly in their layers and topologies and therefore have different memory and computational requirements. In practice, each has proven valuable for image classification.
Single stage detection
Single Shot Detection (SSD) is an object detection model in the MLPerf benchmark; SSD is intended to reflect a simpler and lower latency model for interactive use cases such as in end-point and non-server situations. Notably, SSD uses a pre-trained ResNet-34 backbone as part of the architecture. SSD is trained and evaluated on the COCO dataset (COCO 2017 is large-scale object detection, segmentation and captioning dataset with 80 Object categories, 123,287 Train/val images, and 886,284 instances).
Note the computational overhead of the SSD model is small compared with the ResNet-50 model. The final target is to achieve mean Average Precision of 0.23. The training is done using various NVIDIA-DGX2 multi-gpu configurations i.e. 1, 2, 4, 8 and 16 GPUs. The results are shown in Figure 2.
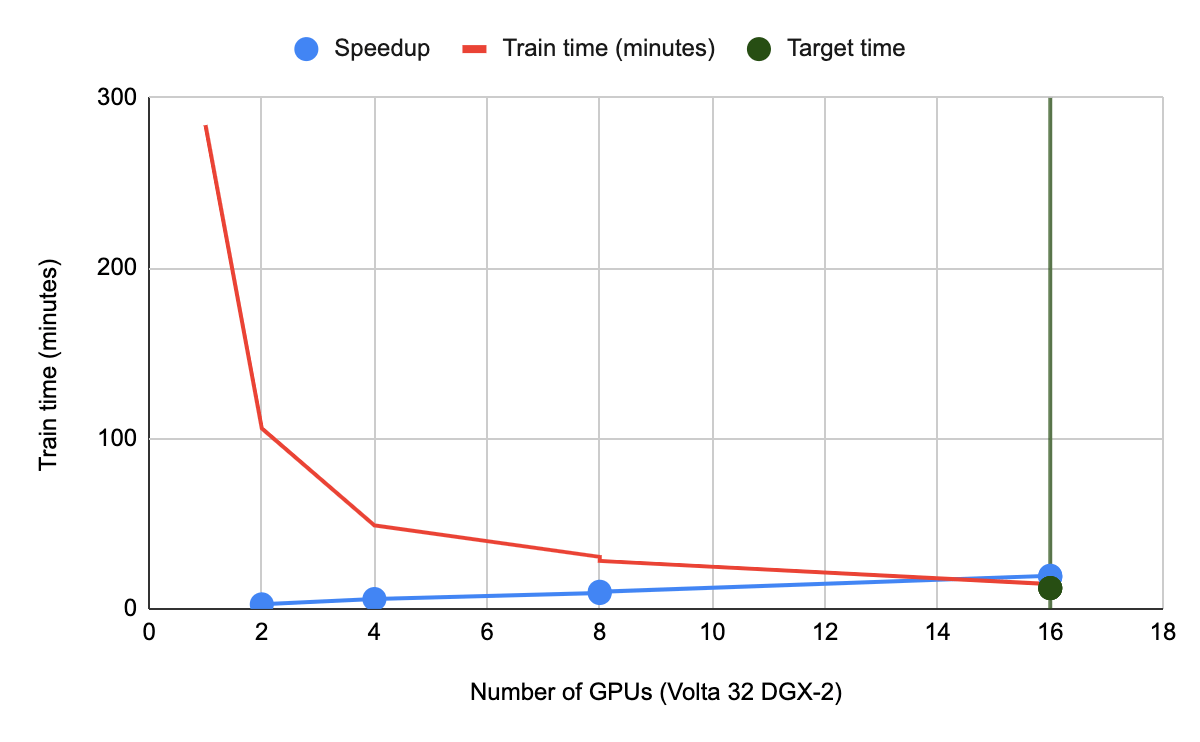
Figure 2: Training time vs number of GPUs used. The green line is the target train time benchmarked by NVIDIA for 16 DGX2 GPUs.
This material is based upon work supported by the National Science Foundation under grant number 1833317. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.